2021年8月から約9ヶ月をかけて、自宅サーバーを構築しました。
 自宅仮想環境
自宅仮想環境
まだまだやることは残っているのですが、とりあえず一区切りということでブログで振り返ります。
TL;DR
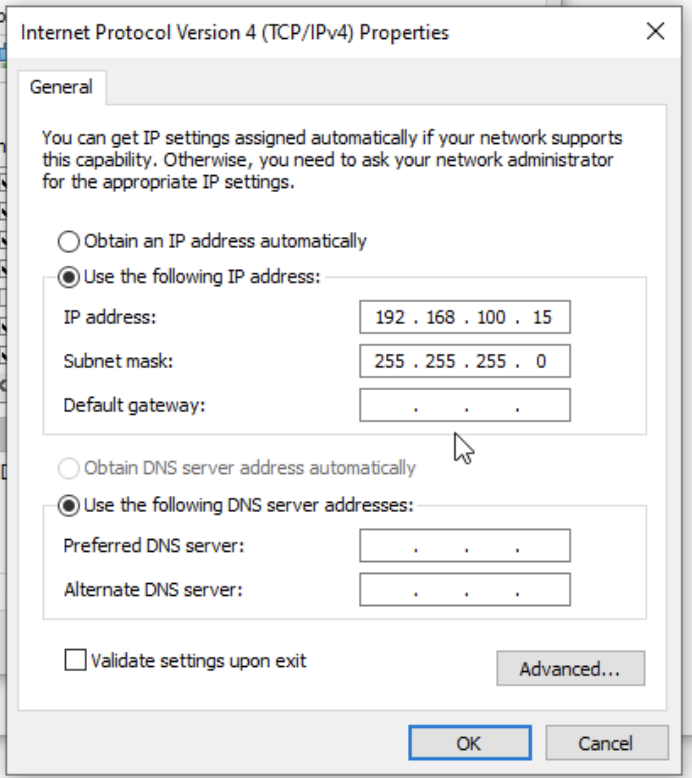
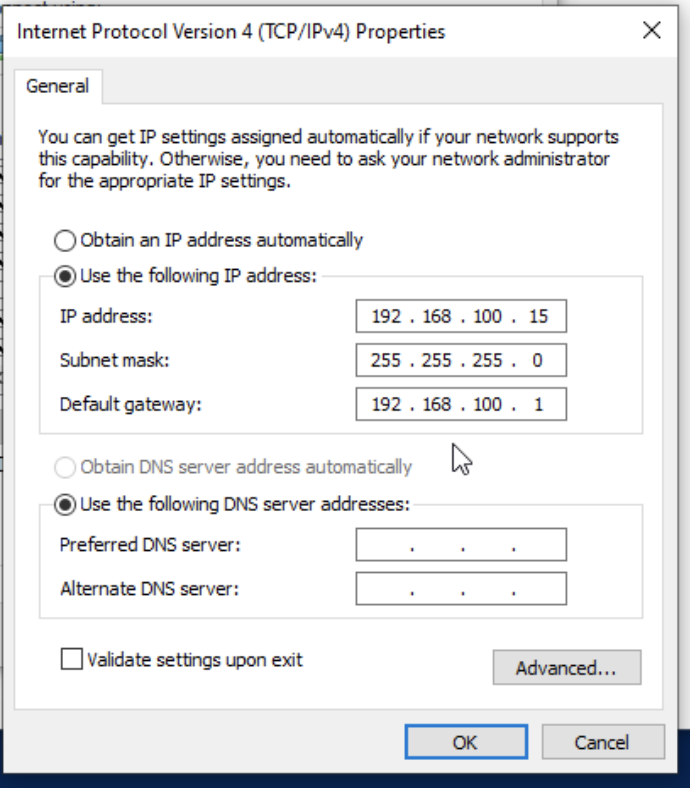
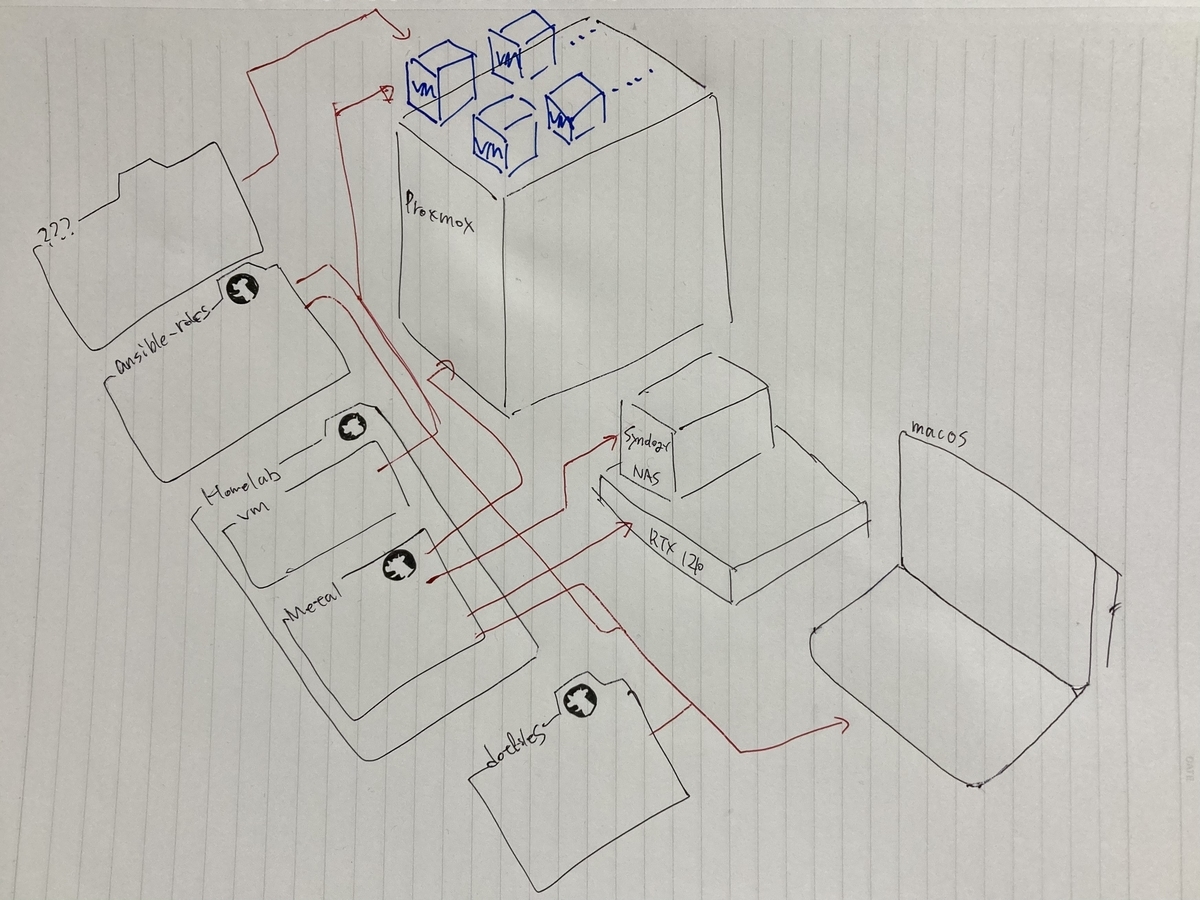
以下のような構成です。
 自宅サーバー構成
自宅サーバー構成
構築にあたってルーター、自作PC、ファイルサーバーを全て1から揃え、構成管理のためにAnsibleを新たに学びました。
スケジュールは以下の通りでした。
 自宅サーバー スケジュール
自宅サーバー スケジュール
当初UbuntuとKVMで仮想環境を構築しようとしていたときは先が見えなくて辛かったのですが、偶然にも同僚にProxmoxを教えてもらったことで先が開けました(ありがとうございます)
自分一人では辿り着けなかったのが悔しいですが、土地勘がないジャンルだとこうなるぞという教訓かもしれません。
設定をGitHubで公開する事にこだわった一方で、セキュリティの観点から「隠すべきものは隠す」ことをどう両立するかに頭を悩ませました。
その結果としてGitLabを立てることに思い至ったのですが、これはKubernetesとそのエコシステムをいっぺんに相手にせねばならず、結果挫折しました。
まとめると、早いうちから経験者にレビューしてもらうべきだったなと思います。
動機
簡単にまとめると以下のとおりです。
- オンプレのインフラを管理したことがなかったのがコンプレックスだった
- 職場のWindows使いの方が困ったときなどに、手軽に再現できる環境がほしかった
- Kubernetesなどを試す上で、クラウド上にクラスターを組むと毎月1万円以上かかってしまう
- ちょっとした用事でLinuxを使いたいときに、いちいちEC2を立ち上げるのがストレス
- プライベートの開発環境が欲しかったが、会社貸与のMacBook以外にもう一台MacBookを買うのはつまらなかった
- 趣味の写真やPDF化した漫画などをNASサーバーで管理したかった
私の欲しいものは「仮想環境」と「NASサーバー」に大別されるのですが、それらを一つの筐体にまとめるかがポイントでした。
結論から言うと仮想環境とNASサーバーは別マシンにし、かつNASサーバーにはSynology NASを選定しました。
マシンをまとめることで場所や電気代が小さくなることが期待された一方で、仮想環境の構築が初めてであったこと、NASサーバーに保存したいデータの重要性から判断しています。
いまでもTrueNASに興味はあるものの、Proxmoxで精一杯なのと、クラウドとの連携やGitなどの機能が搭載されている点から、Synology NASを選んだのは良い判断でした。
仮想環境
ハイパーバイザー型の仮想化を考えていました。XenかKVMかではKVMを採用するとして、以下の管理ツールが候補でした。
せっかくならOSSとして貢献できそうなProxmoxを選定。同僚が使っていたのもポイントでした。せっかくなら同じものを使って盛り上がりたいですからね。
ハードウェア
以下のとおりです。しっかり正規価格って感じです。
 自作PC ハードウェア
自作PC ハードウェア
CPUはAPUなのですが、GPUパススルーができるのか今後の課題です。
SSDに関しては、今から買うなら日本製を応援する意味でキオクシアかもしれません。
ソフトウェア管理
Ansibleで管理し、PlaybookとRoleをそれぞれGitHubで公開しています。
 構成管理
構成管理
homelab
github.com
AnsibleのPlaybookを管理しているリポジトリです。GitHubの homelab タグを参考にしました。
RTX1210, Synology NAS, Proxmox, MacbookおよびゲストOSを全て管理しています。ただし、設定を使い回す予定があるものはAnsible Roleに切り出しています。
PoetryとMakefileの併用で、面倒な設定なく動かしやすいのが気に入っています。
ansible-roles
github.com
複数のPlaybookで共有する予定のあるRoleを切り出しました。
特に気に入っているのは、macOSのdefaultsコマンドの実行を自動化し、一部テストも書いた defaults と、開発マシンに必要な設定を詰め込んだ dev です。なお、面倒で Ansible Galaxyには公開していません。
dotfiles
github.com
もう3年近く運用しているmacOSの設定ファイル集です。
Ansibleを学んだことで、動的な設定はAnsible、静的な設定ファイルはdotfilesというように、切り分けがなされました。
せっかく仮想環境を作ったにもかかわらず、基本的にはWindowsばかり使っています。
古のプログラムで動かしてみたいものがあるような場合だと、macOSには対応していないこともあるので助かっています。
それ以外だと、(いまやMultipassもありますが)Ubuntuにちょっと入ってBSDとのコマンドの挙動の違いを調べたいときなんかにも便利です。
セキュリティの研究やゲームで活躍してくれるのはこれからですね。
もし時間を巻き戻せるなら...
- 思い立ってからハードウェア購入までに2ヶ月。時間の方が貴重なので、後でマシン買い直すくらいの勢いでとりあえず始めてしまってもよかったかも
- 構成図を描いて、経験者の人にアドバイスをもらうべきだった
- KubernetesとGitLabの導入は当初からスコープ外にすべきだった
一方、時間を巻き戻せるとしても同じようにやるだろう、というのは、
- Ansibleを前提としてサーバーの設定管理を学んだのは完全に正解。IaCは一番初めから導入すべき。
- バックアップからの切り戻しは後回しにせず本番前にやるべき
まとめ
9ヶ月かけて自宅サーバーを構築した結果、失敗や迷走も多かったものの、ハードウェアの土地勘やAnsible、Linuxの動かし方を理解することが出来ました。
この環境を使って新たなチャレンジができればと思っています。